Die Zeichenfehlerrate misst die Leistung des Modells; der Lernkurvendiagramm zeigt, wie das Modell während des Trainings gelernt hat
Vorheriger Schritt: Modell-Einrichtung und Training
Zeichenfehlerrate
Die Leistung eines Modells wird auf der Grundlage des „Abstands“ zwischen einer perfekten Transkription (Ihrer Ground Truth) und dem automatisch erkannten Text bestimmt und anhand die Zeichenfehlerrate (Character Error Rate - CER) gemessen.
Die Zeichenfehlerrate ist der Prozentsatz der Zeichen, die vom Texterkennungsmodell falsch transkribiert wurden.
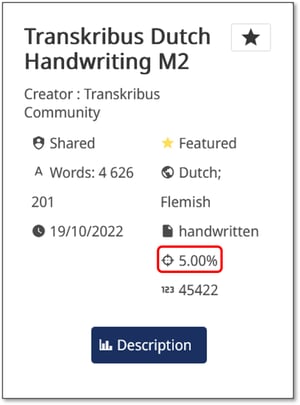
Zum Beispiel bedeutet eine 5% CER, dass das Textmodell automatisch 95 von 100 Zeichen korrekt transkribiert hat, während es nur 5 Zeichen falsch gelesen hat.
Die CER, die Sie unter den Details des Modells im Modellmanager sehen, wird auf den Seiten der Validierungsdaten gemessen und zeigt, wie das Texterkennungsmodell auf Seiten funktioniert, auf denen es nicht trainiert wurde.
 Ergebnisse mit einem CER von 10% oder weniger können als sehr effizient für die automatisierte Transkription angesehen werden. Wenn das Modell jedoch auf Hände aufgetragen wird, die während des Trainings nicht zu sehen sind, oder auf Scribble-Noten, kann es schlechter abschneiden. Ergebnisse mit einem Cer von 20-30% reichen aus, um mit leistungsstarken Suchwerkzeugen wie Smart Search zu arbeiten.
Ergebnisse mit einem CER von 10% oder weniger können als sehr effizient für die automatisierte Transkription angesehen werden. Wenn das Modell jedoch auf Hände aufgetragen wird, die während des Trainings nicht zu sehen sind, oder auf Scribble-Noten, kann es schlechter abschneiden. Ergebnisse mit einem Cer von 20-30% reichen aus, um mit leistungsstarken Suchwerkzeugen wie Smart Search zu arbeiten.
Eine gute CER für gedruckten Text liegt zwischen 0,5 und 2%, während sie für handschriftlichen Text zwischen 2 und 8% liegt, je nachdem, ob das Modell mit einer oder mehreren Händen trainiert wurde.
Lernkurve
Das Diagramm "Lernkurve" zeigt die Genauigkeit Ihres Modells an. Öffnen Sie die Beschreibung des Modells, um es zu sehen.
Die y-Achse stellt die Zeichenfehlerrate dar. Die Kurve geht mit dem Fortschreiten des Trainings und der Verbesserung des Modells nach unten.
Die x-Achse repräsentiert die Epochen, d. h. den Trainingsfortschritt. Während des Trainingsprozesses nimmt Transkribus nach jeder Epoche eine Bewertung vor.
In der Abbildung unten wurden 109 Epochen trainiert. In diesem Fall wurde die maximale Anzahl der Epochen auf 250 festgelegt, aber das Training wurde automatisch bei 109 abgebrochen, da sich das Modell nicht mehr verbesserte. 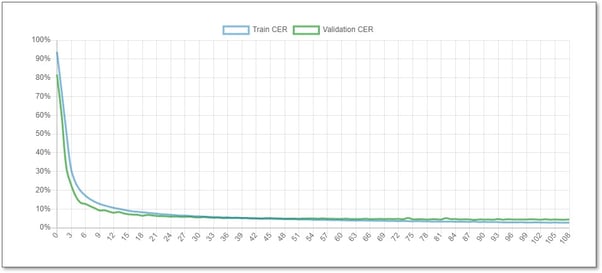
Das Diagramm zeigt zwei Linien, eine in blau und eine in grün. Die blaue Linie stellt den Fortschritt des Trainings dar. Die grüne Linie stellt den Fortschritt der Bewertungen der Validierungsdaten dar. Die Validierungs-CER ist repräsentativer, da sie zeigt, wie das Modell auf neuen Seiten funktionieren sollte, die während der Schulung nicht angezeigt werden.
Nächster Abschnitt: Genauigkeit berechnen
Transkribus eXpert (veraltet)
Zeichenfehlerrate
Die Leistung eines Modells wird auf der Grundlage des „Abstands“ zwischen einer perfekten Transkription (Ihrer Ground Truth) und dem automatisch erkannten Text bestimmt. Sie wird anhand der Zeichenfehlerrate (Character Error Rate - CER) gemessen, d. h. dem Prozentsatz der Zeichen, die vom Texterkennungsmodell falsch transkribiert wurden.
In den Details des Modells sehen Sie die CER sowohl im Training als auch im Validation Set. 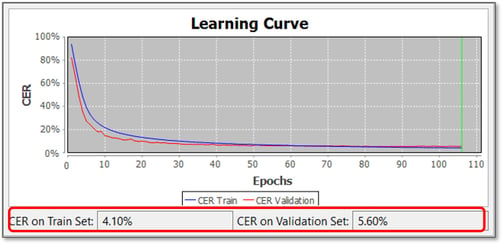
Die repräsentativste CER wird am Validierungsset gemessen, da sie zeigt, wie das Modell auf Seiten funktioniert, auf denen es nicht trainiert wurde.
Ergebnisse mit einem CER von 10% oder weniger können als sehr effizient für die automatisierte Transkription angesehen werden. Wenn das Modell jedoch auf Hände aufgetragen wird, die während des Trainings nicht zu sehen sind, oder auf Kritzelnotizen, kann es schlechter abschneiden. Ergebnisse mit einem CER von 20-30% reichen aus, um mit leistungsstarken Suchwerkzeugen wie Smart Search zu arbeiten.
Lernkurve
Das Diagramm „Lernkurve“ zeigt die Genauigkeit Ihres Modells an.
Die y-Achse stellt die Zeichenfehlerrate dar. Die Kurve geht mit fortschreitendem Training und Verbesserung des Modells nach unten.
Die x-Achse repräsentiert die Epochen, d. h. den Trainingsfortschritt. Während des Trainingsprozesses nimmt Transkribus nach jeder Epoche eine Auswertung vor.
In der folgenden Abbildung wurden 109 Epochen trainiert. In diesem Fall wurde die maximale Anzahl der Epochen auf 250 festgelegt, aber das Training wurde automatisch bei 109 abgebrochen, da sich das Modell nicht mehr verbesserte. 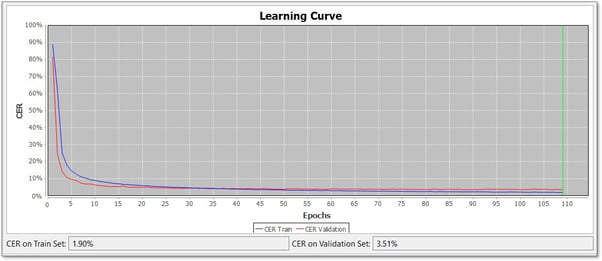
Das Diagramm zeigt zwei Linien, eine in blau und eine in rot. Die blaue Linie stellt den Fortschritt des Trainings dar. Die rote Linie stellt den Fortschritt der Bewertungen im Validierungsset dar.