Tutto ciò che occorre sapere prima di addestrare un modello di riconoscimento del testo: come selezionare i dati di addestramento e di convalida, aggiungere un modello di base e impostare i parametri avanzati
Fase precedente: Preparazione dei dati
Una volta ottenute le pagine di Ground Truth, è il momento di addestrare il modello di riconoscimento del testo.
Fare clic sulla scheda "Formazione" nella barra superiore a destra di "Postazione di lavoro". Quest'area è dedicata all'addestramento di modelli di riconoscimento del testo e di modelli baselines. Il modello di riconoscimento del testo è selezionato come impostazione predefinita quando si apre la pagina.
Prima di tutto, è necessario selezionare la raccolta contenente la Ground Truth. Digitate il titolo della collezione o l'ID della collezione e selezionatelo.
Si tenga presente che non è possibile selezionare documenti da collezioni diverse durante l'addestramento. Per ovviare a questo problema, prima di iniziare l'addestramento, è possibile collegare documenti appartenenti a collezioni diverse a un'unica collezione, come spiegato nella pagina Gestione dei documenti.
Dopo aver scelto la collezione, inizia l'impostazione dell'addestramento vero e proprio.
1. Impostazione del modello
La prima informazione che viene richiesta è quella dei metadati del modello, in dettaglio:
- Nome del modello (scelto dall'utente);
- Descrizione del modello e dei documenti su cui è stato addestrato (materiale, periodo, numero di mani, come sono state trattate le abbreviazioni...);
- Lingua(e) dei vostri documenti;
- L'arco temporale dei vostri documenti;
I metadati vi aiuteranno in seguito a filtrare la ricerca e a trovare più facilmente un modello.
Si può quindi decidere quale versione della trascrizione utilizzare per la formazione: l'ultima trascrizione o solo il Ground Truth. Con la prima opzione, tutte le ultime trascrizioni, indipendentemente dallo status con cui cui sono state salvate, vengono visualizzate e possono essere selezionate per la formazione. Se si sceglie "Solo Ground Truth", sono selezionabili solo le pagine salvate come Ground Truth.
2. Dati di formazione
Durante l'addestramento, le pagine Ground Truth vengono suddivise in due gruppi:
- Dati di training: insieme di esempi utilizzati per adattare i parametri del modello, cioè i dati su cui si basa la conoscenza della rete. Il modello viene addestrato su quelle pagine.
- Dati di convalida: insieme di esempi che fornisce una valutazione imparziale di un modello, utilizzata per mettere a punto i parametri del modello durante l'addestramento. In altre parole, le pagine dei dati di convalida sono messe da parte durante l'addestramento e vengono utilizzate per valutarne l'accuratezza.
Scegliere qui le pagine da includere nei dati di training. Selezionando la casella vicino al titolo del documento, è possibile selezionare tutte le trascrizioni disponibili nel documento. Ma è anche possibile fare clic sul pulsante più, espandere il contenuto del documento e selezionare solo alcune pagine. Le pagine selezionate verranno elencate sulla destra.
Le pagine che non contengono alcuna trascrizione non possono essere selezionate. Per visualizzare il documento o una pagina in una nuova scheda, fare clic sull'icona dell'occhio.
3. Dati di convalida
Selezionare le pagine da assegnare ai Dati di convalida.
Ricordate che i Dati di convalida devono essere rappresentativi del Ground Truth e comprendere tutti gli esempi (scritture, mani, lingue...) inclusi nei Dati di training. Altrimenti, se i dati di convalida sono troppo poco variati, la misurazione delle prestazioni del modello potrebbe essere falsata.
Consigliamo di non risparmiare gli sforzi sui Dati di conbalida e di assegnare ad esso circa il 10% delle trascrizioni di Ground Truth.
È possibile selezionare le pagine manualmente o assegnarle automaticamente. La selezione manuale funziona come descritto sopra per i dati di training. Sono selezionabili solo le pagine che contengono testo e che non sono state incluse nei Dati di training.
Con la selezione automatica, il 2%, il 5% o il 10% dei Dati di training viene assegnato automaticamente ai Dati di convalida: in questo caso, è sufficiente fare clic sulla percentuale che si desidera assegnare. La selezione automatica è consigliata per avere una maggiore varietà di dati di convalida.
4. Motore
PyLaia è il motore di riconoscimento del testo disponibile in Transkribus. Quando si addestra un modello di riconoscimento del testo, questo viene addestrato con PyLaia.
In futuro, speriamo di implementare nuove architetture in Transkribus e di offrire più soluzioni di riconoscimento del testo agli utenti.
5. Parametri avanzati
L'ultima sezione contiene una panoramica della configurazione del modello.
Qui, in fondo alla pagina, si possono modificare i parametri avanzati:
- Epochs:
Il numero di epochs si riferisce al numero di volte in cui l'algoritmo di apprendimento esaminerà tutti i dati di addestramento e si valuterà sia sui dati di training che su quelli di convalida.
Il numero in questa sezione indica il numero massimo di epochs di addestramento, perché l'addestramento verrà interrotto automaticamente quando il modello non migliorerà più (cioè avrà raggiunto il CER più basso possibile). Per cominciare, ha senso attenersi all'impostazione predefinita di 250. - Arresto anticipato (Early Stopping):
Questo valore indica il numero minimo di epochs per l'addestramento: il modello eseguirà almeno questo numero di epochs.
Al termine di queste epochs, se il CER dei dati di convalida continua a diminuire, l'addestramento continuerà e terminerà automaticamente quando il modello non migliorerà più. D'altra parte, se il CER non scende più, l'addestramento viene interrotto.
In altre parole, si obbliga il modello ad allenarsi almeno tante epochs quanto il valore indicato come arresto anticipato.
Per la maggior parte dei modelli, l'impostazione predefinita di 20 epochs funziona bene e si consiglia di lasciarla così per il primo addestramento.
Quando i dati di convalida sono poco o per nulla variati, il modello potrebbe fermarsi troppo presto. Per questo motivo, si consiglia di creare dati di convalida varii, contenenti tutti i tipi di mani e di documenti presenti nei dati di training. Solo se i Dati di convalida sono piuttosto piccoli, si consiglia di aumentare il valore di Arresto anticipato per evitare che l'addestramento si fermi prima di aver visto tutti i Dati di training. Tenete però presente che aumentando il valore, l'addestramento richiederà più tempo. - Modello base:
I modelli esistenti possono essere usati come punti di partenza per addestrare nuovi modelli. Quando si seleziona un modello di base, l'addestramento non parte da zero ma dalle conoscenze già apprese dal modello di base.
Con l'aiuto di un modello di base, è possibile ridurre la quantità di nuove pagine di Ground Truth, accelerando così il processo di addestramento. Probabilmente il modello di base migliorerà anche la qualità dei risultati del riconoscimento.
Il vantaggio di un modello di base, tuttavia, non è sempre garantito e deve essere testato per il caso specifico.
Per utilizzare un modello di base, è sufficiente selezionare quello desiderato. È possibile selezionare uno dei modelli pubblici o un proprio modello PyLaia. Ricordate che, per essere efficace, il modello di base deve essere stato addestrato su uno stile di scrittura simile a quello del vostro modello. - Reverse text (RTL):
Utilizzare questa opzione per invertire il testo durante l'addestramento quando la direzione di scrittura nell'immagine è opposta a quella della trascrizione, ad esempio il testo è stato scritto sul documento da destra a sinistra ma trascritto in Transkribus da sinistra a destra. - Addestrare i tag testuali
Questa funzione non è attualmente supportata da Transkribus. Nel frattempo, è possibile utilizzarlo all'interno di Transkribus eXpert.
Dopo aver controllato tutti i dettagli e aver eventualmente modificato i parametri avanzati, cliccate su "Inizia il training" per avviare l'addestramento.
È possibile seguire l'andamento della formazione facendo clic sul pulsante "Jobs" nel menu a sinistra di "Transkribus Organizer". Il completamento di ogni epoc verrà mostrato nella descrizione del job e si riceverà un'e-mail quando il processo di addestramento è completato.
A seconda del traffico sui server e della quantità di materiale, la formazione potrebbe richiedere un po' di tempo. Nella sezione "Jobs", potete controllare la vostra posizione nella coda (cioè il numero di modelli che vi precedono). È possibile eseguire altri lavori in Transkribus o chiudere la piattaforma durante il processo di addestramento. Se lo stato del job è "creato" o "in esecuzione", non iniziate una nuovo training, bisogna solo avere pazienza e aspettare.
Una volta terminato l'addestramento, è possibile utilizzare il modello per riconoscere nuovi documenti, come spiegato in questa pagina.
Leggete la pagina Gestione dei modelli per imparare a gestire e condividere i modelli.
Prossimo passo: Character Error Rate e curva di apprendimento
Transkribus eXpert (deprecato)
Una volta ottenute le pagine di Ground Truth, è il momento di addestrare il modello di riconoscimento del testo.
Fare clic sulla scheda "Strumenti". Nella sezione "Formazione del modello", fare clic su "Formazione di un nuovo modello". Viene visualizzata la finestra Model Training. Per impostazione predefinita, viene selezionato "PyLaia HTR", il motore che ci interessa per addestrare il modello di riconoscimento del testo, come mostrato nella figura seguente.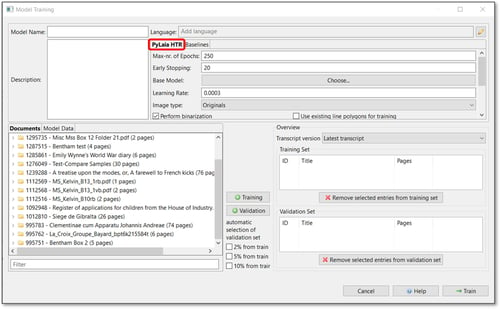
1. Impostazione del modello
Nella sezione superiore, è necessario aggiungere i dettagli relativi al modello:
- Nome del modello (scelto dall'utente);
- Lingua (dei documenti):
- Descrizione (del modello e dei documenti su cui è addestrato).
2. Dati di training
Durante l'addestramento, le pagine di Ground Truth sono divise in due gruppi:
- Dati di training o Training Set: insieme di esempi utilizzati per adattare i parametri del modello, cioè i dati su cui si basa la conoscenza della rete. Il modello viene addestrato su quelle pagine.
- Dati di convalida o Validation Set: insieme di esempi che fornisce una valutazione imparziale di un modello, utilizzato per mettere a punto i parametri del modello durante l'addestramento. In altre parole, le pagine dei Dati di convalida sono messe da parte durante l'addestramento e vengono utilizzate per valutarne l'accuratezza.
Nella parte inferiore della finestra, selezionare innanzitutto le pagine che si desidera includere nel Training Set.
Per aggiungere tutte le pagine del documento, selezionare la cartella e fare clic su "+Training".
Per aggiungere una sequenza specifica di pagine del documento al Training Set, fare doppio clic sulla cartella, fare clic sulla prima pagina che si desidera includere, tenere premuto MAIUSC sulla tastiera e quindi fare clic sull'ultima pagina. Poi cliccate su "+Training".
Per aggiungere singole pagine del documento al Training Set, fare doppio clic sulla cartella, tenere premuto CTRL" sulla tastiera e selezionare le pagine che si desidera utilizzare come dati di addestramento. Poi cliccate su "+Training".
Le pagine selezionate appariranno nello spazio "Training Set" sulla destra.
Al di sopra, si può decidere quale versione di trascrizione si vuole usare sia per il Traning Set che per il Validation Set: l'ultima trascrizione, solo il Ground Truth o la trascrizione iniziale. Con la prima opzione, tutte le ultime trascrizioni, indipendentemente dallo status con cui sono state salvate, vengono visualizzate e possono essere selezionate per la formazione. Se si sceglie "Only Ground Truth", sono selezionabili solo le pagine salvate come Ground Truth.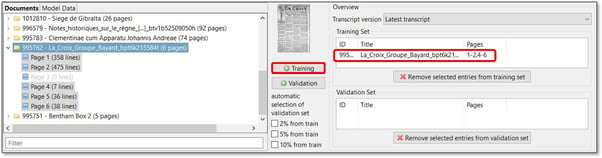
3. Dati di convalida
Ricordate che il Validation Set deve essere rappresentativo del Ground Truth e comprendere tutti gli esempi (scritture, mani, lingue...) inclusi nel Training Set. Altrimenti, se il Validation Set è troppo poco vario, la misurazione delle prestazioni del modello potrebbe essere falsata.
Consigliamo di non risparmiare sforzi sull'insieme di convalida e di assegnargli circa il 10% delle trascrizioni di Ground Truth.
Per aggiungere pagine al Validation Set, seguire la stessa procedura spiegata sopra per il set di addestramento, ma fare clic sul pulsante "+Validation".
È anche possibile assegnare automaticamente il 2%, il 5% o il 10% del Training Set al Validation Set. Selezionare le pagine da aggiungere al Training Set, contrassegnare la percentuale che si desidera assegnare al Validation Set e fare clic sul pulsante "+Training".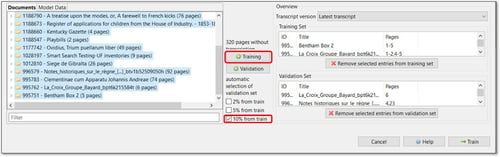
Per rimuovere le pagine dal Training Set o dal Validation Set, fare clic sulla pagina e poi sul pulsante con la croce rossa.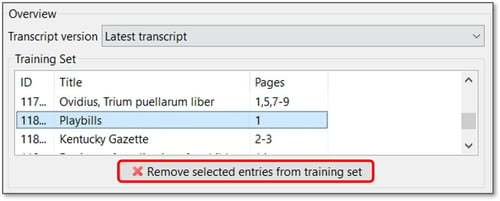
4. Motore
PyLaia è il motore di riconoscimento del testo disponibile all'interno di Transkribus. Quando si addestra un modello di riconoscimento del testo, questo viene addestrato con PyLaia.
In futuro, speriamo di implementare nuove architetture in Transkribus e di offrire più soluzioni di riconoscimento del testo agli utenti.
5. Parametri avanzati
I parametri per il motore PyLaia in Transkribus eXpert sono suddivisi in due gruppi:
- "Parametri standard" (nella sezione in alto a destra della finestra, sotto "Lingua");
- "Parametri avanzati" (accessibile facendo clic sul pulsante in fondo alla sezione Parametri).
Parametri standard:
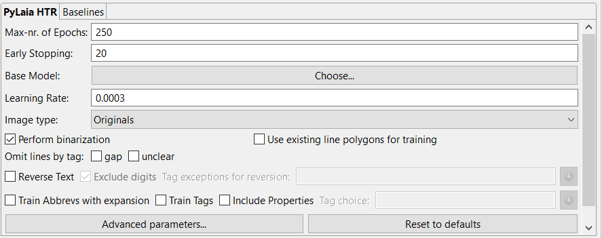
In dettaglio, sono:
- Max-nr. of Epochs:
Il numero di epoche si riferisce al numero di volte in cui l'algoritmo di apprendimento lavorerà attraverso gli interi dati di addestramento e valuterà se stesso sia sui dati di addestramento che su quelli di validazione.
È possibile aumentare il numero massimo di epoche, ma occorre tenere presente che il processo di addestramento richiederà più tempo. Inoltre, si noti che l'addestramento viene interrotto automaticamente quando il modello non migliora più (cioè ha raggiunto il CER più basso possibile). Per cominciare, ha senso attenersi all'impostazione predefinita di 250. - Arresto anticipato (Early Stopping):
Questo valore indica il numero minimo di epochs per l'addestramento: il modello eseguirà almeno questo numero di epochs.
Al termine di queste epochs, se il CER dei dati di convalida continua a diminuire, l'addestramento continuerà e terminerà automaticamente quando il modello non migliorerà più. D'altra parte, se il CER non scende più, l'addestramento viene interrotto.
In altre parole, si obbliga il modello ad allenarsi almeno tante epochs quanto il valore indicato come arresto anticipato.
Per la maggior parte dei modelli, l'impostazione predefinita di 20 epochs funziona bene e si consiglia di lasciarla così per il primo addestramento.
Quando i dati di convalida sono poco o per nulla variati, il modello potrebbe fermarsi troppo presto. Per questo motivo, si consiglia di creare dati di convalida varii, contenenti tutti i tipi di mani e di documenti presenti nei dati di training. Solo se i Dati di convalida sono piuttosto piccoli, si consiglia di aumentare il valore di Arresto anticipato per evitare che l'addestramento si fermi prima di aver visto tutti i Dati di training. Tenete però presente che aumentando il valore, l'addestramento richiederà più tempo. - Modello base (Base model):
I modelli esistenti possono essere usati come punti di partenza per addestrare nuovi modelli. Quando si seleziona un modello di base, l'addestramento non parte da zero ma dalle conoscenze già apprese dal modello di base. Con l'aiuto di un modello di base, è possibile ridurre la quantità di nuove pagine di Ground Truth, accelerando così il processo di formazione. Probabilmente il modello di base migliorerà anche la qualità dei risultati del riconoscimento.
Il vantaggio di un modello di base, tuttavia, non è sempre garantito e deve essere testato per il caso specifico.
Per utilizzare un modello di base, è sufficiente scegliere quello desiderato con il pulsante "Scegli..." accanto a "Modello di base". Potete selezionare uno dei modelli pubblici di PyLaia o un vostro modello di PyLaia.
Ricordate che, per essere efficace, il modello di base deve essere stato addestrato su uno stile di scrittura simile a quello del vostro modello. - Tasso di apprendimento (Learning Rate):
Il "tasso di apprendimento" definisce l'incremento da un'epoca all'altra, quindi la velocità con cui procede l'addestramento. Con un valore più alto, la frequenza di errore dei caratteri diminuirà più rapidamente. Ma più alto è il valore, più alto è il rischio che i dettagli vengano trascurati.
Questo valore è adattivo e verrà regolato automaticamente. L'allenamento è però influenzato dal valore con cui viene avviato. Si può scegliere l'impostazione predefinita. - Tipo di immagine:
Abbiamo avuto alcuni casi in cui la pre-elaborazione richiedeva troppo tempo. Se ciò accade, si può cambiare il "Tipo di immagine" in "Compresso".
Si può procedere nel modo seguente: avviare l'allenamento con "Originale". Quando l'addestramento è iniziato (stato "Running"), di tanto in tanto controllare l'avanzamento della preelaborazione con il pulsante "Jobs". Nel caso in cui si blocchi, è possibile annullare il lavoro e riavviarlo con l'impostazione "Compresso".
- Eseguire la binarizzazione:
Questa opzione è selezionata per impostazione predefinita. Disattivare e non utilizzare la binarizzazione solo se si dispone di dati di addestramento omogenei, cioè pagine con lo stesso colore di sfondo. Solo in questo caso nessuna binarizzazione può portare a risultati migliori. - Usa poligoni lineari esistenti per l'addestramento:
Se si attiva questa opzione, i poligoni lineari non verranno calcolati durante l'addestramento (come avviene per impostazione predefinita), ma verranno utilizzati quelli esistenti.Durante il riconoscimento, quindi, per ottenere le migliori prestazioni del modello addestrato risultante, si dovranno utilizzare poligoni lineari simili.
- Elimina le righe per tag:
Con questa opzione, è possibile omettere dall'addestramento le righe contenenti parole etichettate come "lacuna" e/o "non chiaro". Si noti che durante l'addestramento verrà ignorata l'intera riga, non solo la parola non chiara: questo accade perché l'addestramento avviene a livello di riga. - Invertire il testo:
Utilizzare questa opzione per invertire il testo durante l'addestramento quando la direzione di scrittura nell'immagine è opposta a quella della trascrizione, ad esempio il testo è stato scritto da destra a sinistra e trascritto da sinistra a destra. Si può anche decidere di escludere dalla reversione le cifre o il testo con etichetta. - Addestramento dei tag:
È possibile addestrare i tag testuali e le loro proprietà se sono presenti nella Ground Truth, in modo che il modello generi automaticamente i tag durante il riconoscimento. Questa funzione funziona bene con le abbreviazioni e gli stili di testo e porta i migliori risultati per i tag che si ripetono nello stesso modo (cioè la stessa parola) molto spesso.
Selezionare "Train Abbreviations with tags" per addestrare le abbreviazioni con tag (tag "Abbrev") e le rispettive proprietà "expansion" presenti nella Ground Truth.
Per gli altri tag, selezionare l'opzione "Train Tags" e fare clic su "Include Properties". Utilizzare il pulsante verde più per inserire l'elenco dei tag che devono essere addestrati. Si tenga presente che qui si possono selezionare solo i tag che sono stati aggiunti al gruppo "Tag Specification".
Parametri avanzati:
Gli utenti possono impostare autonomamente diversi parametri avanzati di PyLaia. È possibile aprire i parametri avanzati facendo clic sul pulsante "Parametri avanzati" in fondo ai parametri standard.
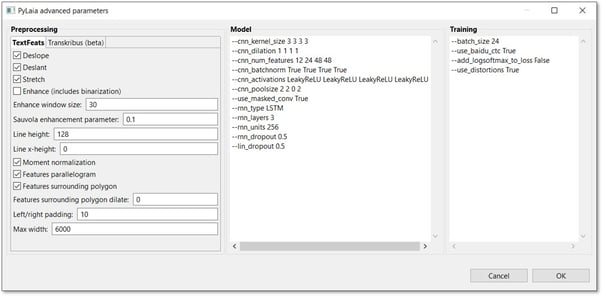
Si dividono in tre gruppi: Preelaborazione, Modello e Addestramento.
- Parametri di pre-elaborazione:
- Deslant: scegliere questa opzione con la scrittura corsiva per raddrizzarla. Tralasciare questa opzione con i documenti stampati perché se i documenti stampati contengono passaggi in corsivo oltre ai normali caratteri di stampa, l'effetto può essere capovolto.
- Deslope: consente una maggiore variazione alle linee di base, ad esempio una maggiore tolleranza alle linee di base non esattamente orizzontali ma inclinate.
- Stretch: questa opzione è per le scritte strette, al fine di decomprimerle.
- Migliora: è una finestra che va oltre le linee di base per ottimizzare i passaggi di difficile lettura. Questo è utile se c'è del "rumore" nel documento.
- Migliora dimensione finestra: questa impostazione fa riferimento all'opzione appena spiegata e quindi deve essere impostata solo se si desidera utilizzare "Migliora". Questa impostazione definisce la dimensione della finestra.
- Parametro di potenziamento di Sauvola: attenersi all'impostazione predefinita.
- Altezza della linea: valore in pixel; se è necessario aumentare i pixel della linea, è possibile farlo qui. 100 è un buon valore da scegliere.
Attenzione: se il valore è troppo alto, potrebbe verificarsi un "ordine fuori memoria". È possibile aggirare questo errore abbassando il valore della "dimensione del batch" (in alto a sinistra nella finestra dei parametri avanzati), ad esempio dimezzandolo. Si tenga presente che più basso è questo valore, più lento sarà l'addestramento. Il rallentamento dell'addestramento legato alla dimensione del batch dovrebbe essere migliorato con la nuova versione di PyLaia, che imposterà automaticamente la dimensione del batch. - Linea x-height: questa impostazione si applica ai discendenti e agli ascendenti. Se si inserisce questo valore, il parametro "Altezza linea" verrà ignorato.
- Si prega di non modificare i seguenti quattro parametri:
Normalizzazione del momento
Feature parallelogramma
Feature poligono circostante
Feature poligono circostante dilatato - Padding sinistro/destro: 10 (predefinito) significa che verranno aggiunti 10 pixel. Questo è utile se si teme che alcune parti della linea possano essere tagliate.
- Larghezza massima: larghezza massima che una linea può raggiungere; il resto verrà tagliato. 6000 (valore predefinito) è già un valore elevato. Se si dispone di pagine di grandi dimensioni, è possibile aumentare ulteriormente questo valore.
- Parametri del modello:
Per tutti coloro che hanno familiarità con l'apprendimento automatico e la modifica delle reti neurali. Pertanto, questi parametri non vengono spiegati ulteriormente in questa sede.
- Parametri di formazione:
- Dimensione del lotto: numero di pagine elaborate contemporaneamente nella GPU. È possibile modificare questo valore inserendo un altro numero.
- Uso_distorsioni Vero: l'insieme di allenamento viene esteso artificialmente per aumentare la variazione dell'insieme di allenamento e rendere così il modello più robusto. Se state lavorando su una scrittura uniforme e su buone scansioni, non avete bisogno di questa opzione. Per disattivarlo, scrivere "False" invece di "True".
- La struttura della rete di PyLaia può essere modificata: un campo da gioco per chi ha familiarità con l'apprendimento automatico. Le modifiche alla rete neurale possono essere effettuate tramite il repository di Github.
A questo punto, è possibile avviare l'allenamento facendo clic sul pulsante "Train".
È possibile seguire l'andamento della formazione facendo clic sul pulsante "Jobs" nella scheda "Server". A seconda del traffico sui server e della quantità di materiale, la formazione potrebbe richiedere un po' di tempo. Nella finestra "Jobs", potete controllare la vostra posizione nella coda (cioè il numero di modelli che vi precedono). È possibile eseguire altri lavori in Transkribus o chiudere il programma durante il processo di addestramento. Se lo stato del lavoro è "creato" o "in corso", non iniziate una nuova addestramento, bisogna solo avere pazienza e aspettare.
Dopo l'inizio dell'addestramento, il completamento di ogni epoc verrà mostrato nella descrizione del lavoro e si riceverà un'e-mail quando il processo di addestramento sarà completato.