When working with newspapers, Layout Recognition can be challenging. Use a Field Model first and the advanced configuration settings for line detection second to achieve good results
Previous step: Automatic Layout Recognition
Processing newspapers may be challenging if you run the Text Recognition directly. The issue often lies not in the model's ability to read the text but in Layout Recognition, which is integrated into Text Recognition as its first step.
The solution is to run the Layout and Text Recognition as two separate steps.
For best results, we suggest first using a Field Model to segment the newspaper page (articles and headings as separated text blocks) and then running the Layout Recognition, keeping the existing text regions.
Tweaking the advanced layout configuration settings helps to have all lines recognised for their entire length.
Most depend on the type of newspaper and image quality you are dealing with, so it could be a trial-and-error process. We recommend testing the settings on a few pages before running the Layout Recognition on the entire document.
In general, these are the steps to follow to recognise newspaper layout:
Step 1: Newspaper Page Segmentation (articles, headings...)
This step identifies the text regions. In the case of newspapers, it is essential to segment the page into separate text blocks, such as articles and headings. Otherwise, you will end up with a large text region comprising the entire page, which will result in a mixed-up reading order of the lines.
- Select the document or the specific page(s) you want to process.
- Click on the "Recognise" button.
- Go to the top of the recognition section and choose "Fields."
- Search for a suitable public or private Field model trained to segment newspapers.
- Start the Recognition.
If a Field public model for newspapers is not available or does not perform as expected on your documents, you have the option to train a Field model specifically for your newspapers. This allows you to choose whether you want the model to simply segment the pages into text regions or if you also want to train it to add structural tags (such as article, heading, advertisement, list, figure, etc). For more information on training a Field model, please refer to this article.
Step 2: Layout Recognition with Advanced Settings
- Select the document or the specific page(s) you want to process.
- Click on the "Recognise" button.
- Go to the top of the recognition section and choose "Layout."
- Choose the baseline model and modify the Advanced Settings.
In our experience, these configuration settings have proven effective for most newspapers. However, it is important to note that these settings may vary depending on the quality of the images and the type of newspaper you are working with.
Layout Model Mixed Line Orientation (click on Advanced Settings) Generation of Text Regions (Layout Blocks) Keep existing Image Scaling Upscale (click on Baseline Options) Minimal Baseline Lengh Low Baseline Accuracy Threshold High Use Trained Separators No Max distance for merging baselines Medium Split Lines on Regions border Yes 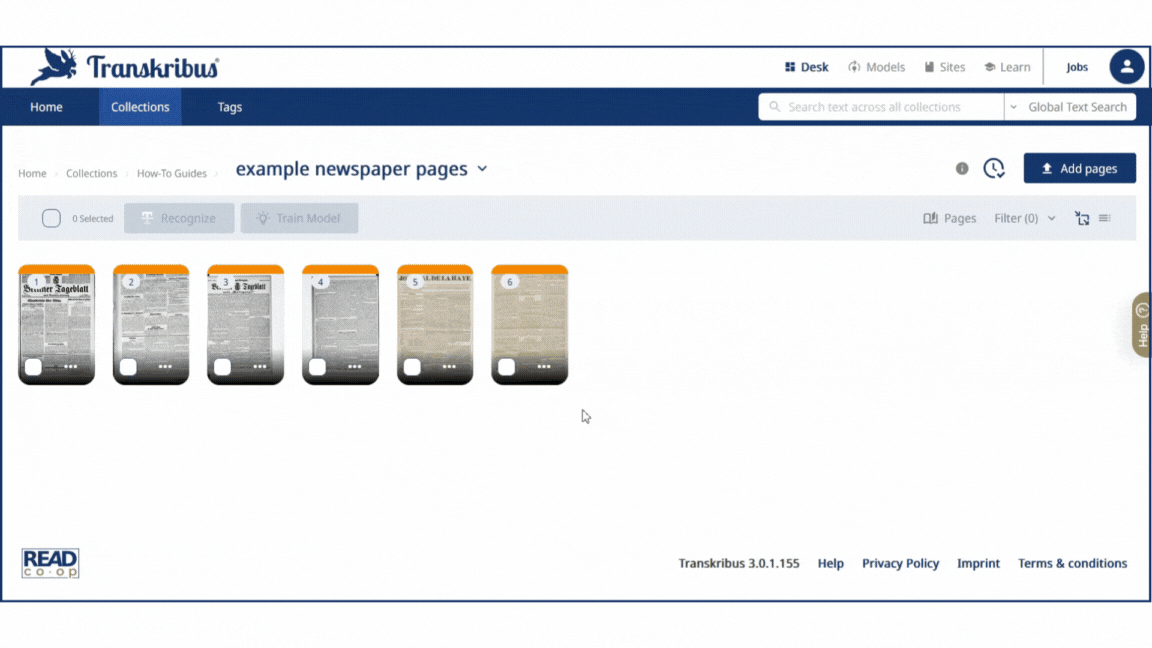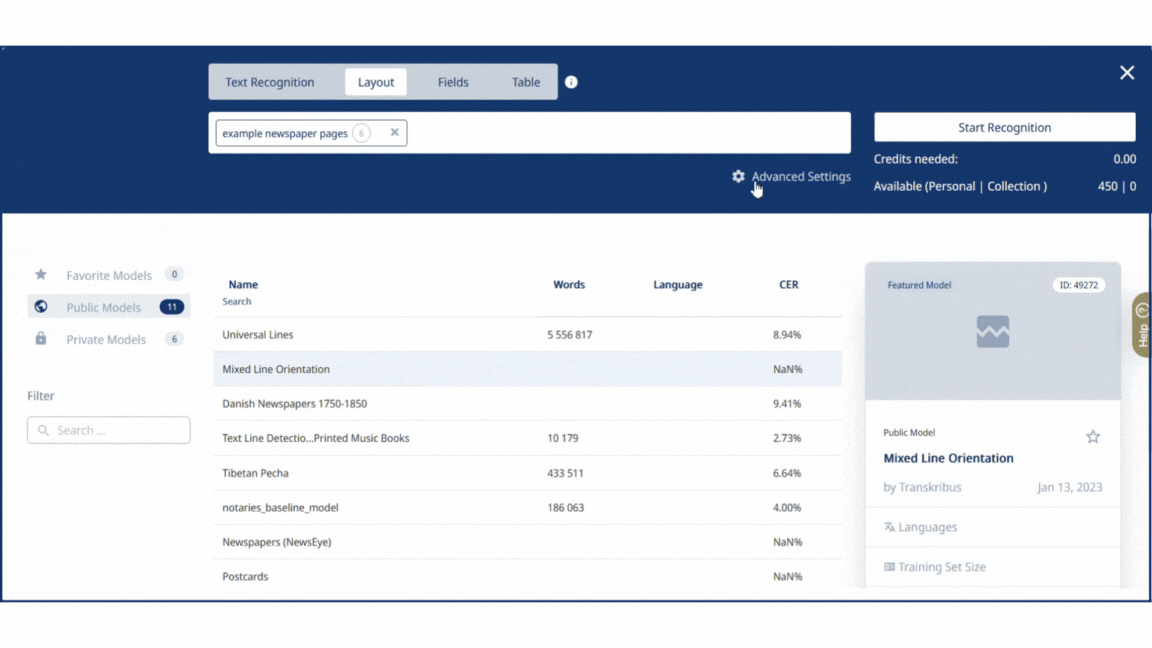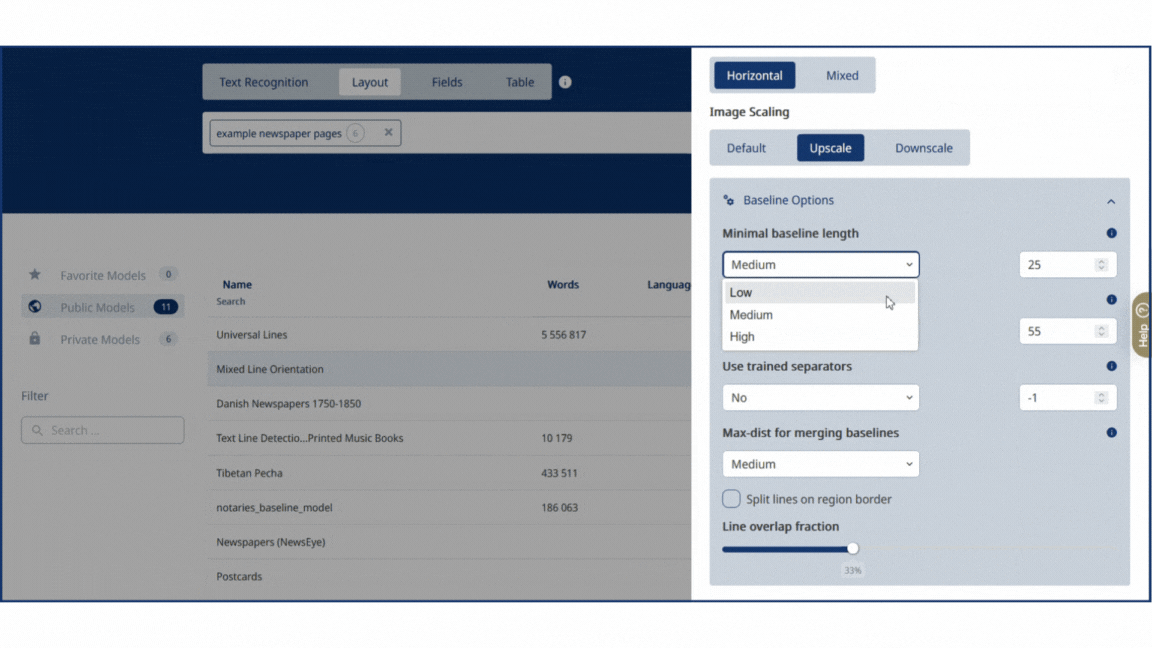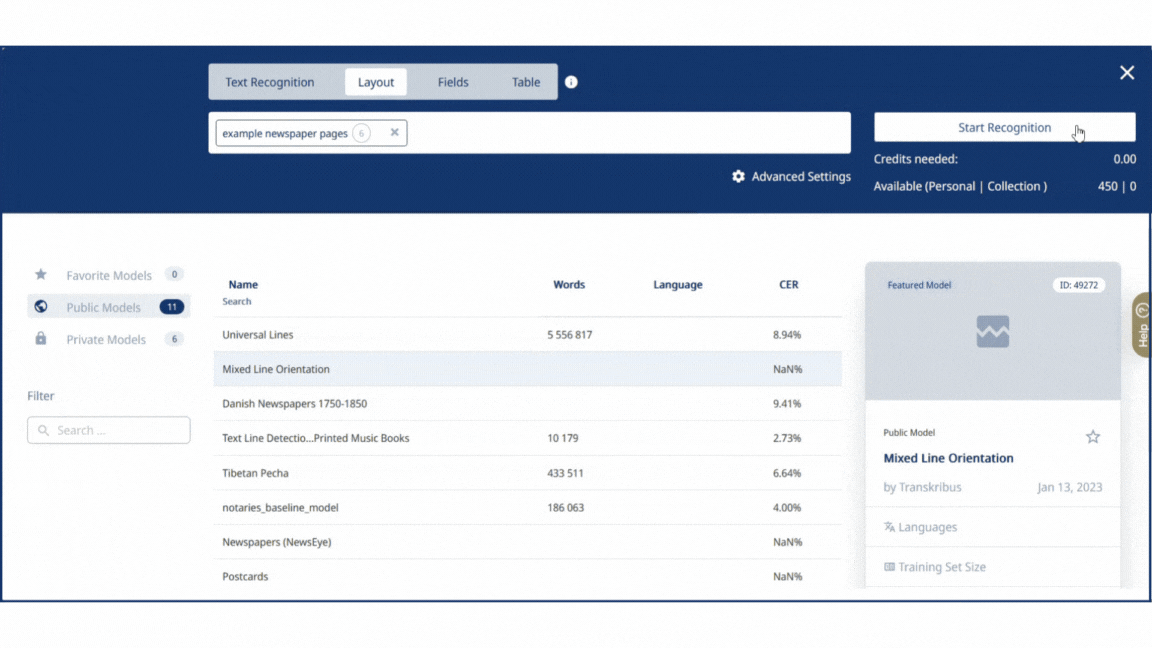
We recommend starting with the suggested settings and adjusting them, if needed, based on the information provided on the Advanced Layout Configuration Settings page.
In certain situations, we have discovered that resizing the images (by doubling their size) before uploading them to Transkribus can be beneficial. - Start the Layout Recognition.
Step 3: Text Recognition
Apply the most appropriate Text Model to automatically transcribe the content of the newspapers, as explained on this page.
Following step: Automatically transcribing your documents