Alles, was Sie vor dem Training eines Texterkennungsmodells wissen müssen: Wie Sie die Trainings- und Validierungsdaten auswählen, ein Basismodell hinzufügen und die erweiterten Parameter einrichten
Vorheriger Schritt: Vorbereiten von Trainingsdaten
Sobald Sie Ihre Ground Truth-Seiten haben, ist es an der Zeit, das Texterkennungsmodell zu trainieren.
Klicken Sie auf die Registerkarte „Training“ in der oberen Leiste rechts neben „Workdesk“. Dieser Bereich ist der Schulung von Texterkennungsmodellen und Baselines-Modellen gewidmet. Das Texterkennungsmodell ist beim Öffnen standardmäßig ausgewählt.
Zuerst müssen Sie die Sammlung auswählen, die Ihre Ground Truth enthält. Geben Sie den Kollektionstitel oder die Kollektions-ID ein und wählen Sie sie aus.
Beachten Sie, dass Sie während der Schulung keine Dokumente aus verschiedenen Sammlungen auswählen können. Um dieses Problem zu beheben, ist es vor Beginn der Schulung möglich, Dokumente, die zu verschiedenen Sammlungen gehören, mit einer einzigen Sammlung zu verknüpfen, wie auf der Seite Verwalten von Dokumenten erläutert.
Nachdem Sie die Sammlung ausgewählt haben, beginnt das richtige Trainings-Setup.
1. Modell-Setup
Die ersten Informationen, die Sie eingeben müssen, sind die Modellmetadaten im Detail:
- Modellname (von Ihnen gewählt);
- Beschreibung Ihres Modells und der Dokumente, auf denen es trainiert ist (Material, Zeitraum, Anzahl der Hände, wie Sie Abkürzungen gehandhabt haben...);
- Sprache(n) Ihrer Dokumente;
- Zeitspanne Ihrer Dokumente.
Die Metadaten helfen Ihnen später, Ihre Suche zu filtern und ein Modell einfacher zu finden.
Sie können dann entscheiden, welche Transkriptversion für die Schulung verwendet werden soll: das letzte Transkript oder nur Ground Truth. Bei der ersten Option werden alle aktuellen Transkripte angezeigt, unabhängig davon, mit welchem Status sie gespeichert wurden, und können für die Schulung ausgewählt werden. Wenn Sie "Nur Ground Truth" wählen, sind nur die als Ground Truth gespeicherten Seiten auswählbar.
2. Trainingsdaten
Während des Trainings sind die Ground Truth-Seiten in zwei Gruppen unterteilt:
- Trainingsdaten: Reihe von Beispielen, die verwendet werden, um die Parameter des Modells anzupassen, d. h. die Daten, auf denen das Wissen im Netz basiert. Auf diesen Seiten wird das Modell trainiert.
- Validierungsdaten: Reihe von Beispielen, die eine unvoreingenommene Bewertung eines Modells ermöglichen, mit denen die Parameter des Modells während des Trainings abgestimmt werden können. Mit anderen Worten werden die Seiten der Validierungsdaten während des Trainings beiseite gelegt und zur Beurteilung ihrer Genauigkeit verwendet.
Wählen Sie hier die Seiten aus, die in die Trainingsdaten aufgenommen werden sollen. Wenn Sie das Kästchen neben dem Titel des Dokuments ankreuzen, können Sie alle im Dokument verfügbaren Transkriptionen auswählen. Sie können aber auch auf die Plus-Schaltfläche klicken, den Inhalt des Dokuments erweitern und nur einige Seiten auswählen. Die ausgewählten Seiten werden auf der rechten Seite aufgelistet.
Die Seiten, die keine Transkription enthalten, können nicht ausgewählt werden. Um das Dokument oder eine Seite in einer neuen Registerkarte anzuzeigen, klicken Sie auf das Augensymbol.
3. Validierungsdaten
Wählen Sie die Seiten aus, die den Validierungsdaten zugewiesen werden sollen.
Denken Sie daran, dass die Validierungsdaten repräsentativ für die Ground Truth sein und alle Beispiele (Skripte, Hände, Sprachen...) umfassen sollten, die in den Trainingsdaten enthalten sind. Andernfalls könnte die Messung der Leistung des Modells verzerrt sein, wenn die Validierungsdaten zu wenig variiert werden.
Wir empfehlen, den Aufwand für das Validierungsset nicht zu sparen und ihm etwa 10 % Ihrer Ground Truth-Transkriptionen zuzuweisen.
Sie können die Seiten manuell auswählen oder automatisch zuweisen. Die manuelle Auswahl funktioniert wie oben für die Trainingsdaten beschrieben. Nur die Seiten, die Text enthalten und nicht in die Trainingsdaten aufgenommen wurden, sind auswählbar.
Bei der automatischen Auswahl werden 2 %, 5 % oder 10 % der Trainingsdaten automatisch den Validierungsdaten zugewiesen: in diesem Fall klicken Sie einfach auf den Prozentsatz, den Sie zuweisen möchten. Die automatische Auswahl wird empfohlen, um vielfältigere Validierungsdaten zu haben.
4. Motor
PyLaia ist die Texterkennungs-Engine, die in Transkribus verfügbar ist. Wenn Sie ein Texterkennungsmodell trainieren, wird es mit PyLaia trainiert.
In Zukunft hoffen wir, neue Architekturen in Transkribus zu implementieren und den Benutzern mehr Texterkennungslösungen anzubieten.
5. Erweiterte Parameter
Der letzte Abschnitt enthält einen Überblick über die Modellkonfiguration.
Hier unten auf der Seite können Sie die erweiterten Parameter ändern:
- Epochen:
Die Anzahl der Epochen bezieht sich auf die Häufigkeit, mit der der Lernalgorithmus die gesamten Trainingsdaten durchläuft und sich sowohl bei den Trainings- als auch bei den Validierungsdaten selbst bewertet.
Die Zahl in diesem Abschnitt gibt die maximale Anzahl der trainierten Epochen an, da das Training automatisch gestoppt wird, wenn sich das Modell nicht mehr verbessert (d. h. die niedrigstmögliche Cer erreicht hat). Zunächst ist es sinnvoll, die Standardeinstellung von 250 einzuhalten. - Early Stopping:
Dieser Wert legt die Mindestanzahl von Epochen für das Training fest: Das Modell wird mindestens so viele Epochen durchlaufen.
Nach Abschluss dieser Epochen, wenn der CER der Validierungsdaten weiter sinkt, wird das Training fortgesetzt und automatisch beendet, wenn sich das Modell nicht mehr verbessert. Wenn die CER hingegen nicht mehr sinkt, wird das Training abgebrochen.
Mit anderen Worten: Mit dem Wert für das frühzeitige Beenden zwingen Sie das Modell, mindestens diese Anzahl von Epochen zu trainieren.
Bei den meisten Modellen funktioniert die Standardeinstellung von 20 Epochen gut, und wir empfehlen, sie für Ihr erstes Training beizubehalten.
Wenn die Validierungsdaten keine oder nur geringe Variationen aufweisen, kann das Modell zu früh aufhören. Aus diesem Grund empfehlen wir, abwechslungsreiche Validierungsdaten zu erstellen, die alle in den Trainingsdaten vorkommenden Handtypen und Dokumenttypen enthalten. Nur wenn Ihre Validierungsdaten eher klein sind, sollten Sie den "Early Stopping"-Wert erhöhen, um zu verhindern, dass das Training aufhört, bevor es alle Trainingsdaten gesehen hat. Beachten Sie aber, dass das Training länger dauert, wenn Sie den Wert erhöhen. - Basismodell:
Bestehende Modelle können als Ausgangspunkt für das Training neuer Modelle verwendet werden. Wenn Sie ein Basismodell wählen, beginnt das Training nicht bei Null, sondern bei dem Wissen, das das Basismodell bereits erlernt hat.
Mit Hilfe eines Basismodells ist es möglich, die Anzahl neuer Ground Truth-Seiten zu reduzieren und so den Trainingsprozess zu beschleunigen. Wahrscheinlich wird das Basismodell auch die Qualität der Erkennungsergebnisse verbessern.
Der Nutzen eines Basismodells ist jedoch nicht immer gewährleistet und muss für den spezifischen Fall getestet werden.
Um ein Basismodell zu verwenden, wählen Sie einfach das gewünschte aus. Sie können eines der öffentlichen Modelle oder ein PyLaia-Modell von Ihnen auswählen. Denken Sie daran, dass das Basismodell, um von Vorteil zu sein, in einem Schreibstil ähnlich dem Ihres Modells trainiert worden sein muss. - Text umkehren (RTL):
Verwenden Sie diese Option, um Text während des Trainings umzukehren, wenn die Schreibrichtung im Bild der Transkription entgegengesetzt ist, z. B. der Text wurde von rechts nach links geschrieben und von links nach rechts transkribiert. - Train Tags
Diese Funktion wird in Transkribus derzeit nicht unterstützt. In der Zwischenzeit können Sie es in Transkribus eXpert verwenden.
Nachdem Sie alle Details überprüft und gegebenenfalls die erweiterten Parameter geändert haben, klicken Sie auf „Training starten“, um das Training zu starten.
Sie können den Fortschritt der Schulung verfolgen, indem Sie auf die Schaltfläche "Jobs" im linken Menü "Transkribus Organizer" klicken. Der Abschluss jeder Epoche wird in der Stellenbeschreibung angezeigt und Sie erhalten eine E-Mail, wenn der Trainingsprozess abgeschlossen ist.
Abhängig vom Datenverkehr auf den Servern und der Menge an Material kann Ihr Training eine Weile dauern. Im Fenster „Jobs“ können Sie Ihre Position in der Warteschlange überprüfen (d. h. die Anzahl der Schulungen vor Ihnen). Sie können andere Aufgaben in Transkribus ausführen oder die Plattform während des Schulungsprozesses schließen. Wenn der Auftragsstatus "erstellt" oder "ausgeführt" ist, beginnen Sie bitte keine neue Schulung, sondern haben Sie einfach Geduld und warten Sie.
Nach Abschluss der Schulung können Sie Ihr Modell verwenden, um neue Dokumente zu erkennen, wie auf dieser Seite erklärt.
Lesen Sie die Seite Verwalten von Modellen, um zu erfahren, wie man Modelle verwaltet und teilt.
Nächster Abschnitt: Zeichenfehlerrate (CER) und Lernkurve
Transkribus eXpert (veraltet)
Sobald Sie Ihre Ground Truth-Seiten haben, ist es an der Zeit, das Texterkennungsmodell zu trainieren.
Klicken Sie auf die Registerkarte „Extras“. Klicken Sie im Abschnitt „Model Training“ (Modellschulung) auf „Train a new model“ (Ein neues Modell trainieren). Das Fenster Modellschulung öffnet sich. Standardmäßig wird „PyLaia HTR“, die Engine, an der wir interessiert sind, um das Texterkennungsmodell zu trainieren, ausgewählt, wie in der folgenden Abbildung gezeigt.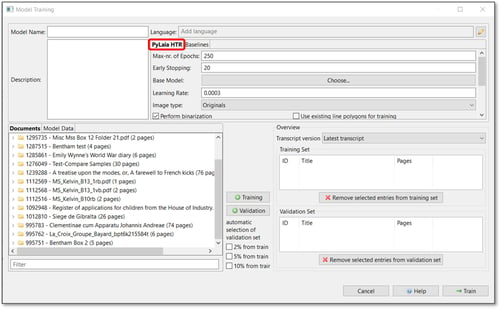
1. Modell-Setup
Im oberen Abschnitt müssen Sie Details zu Ihrem Modell hinzufügen:
Modellname (von Ihnen gewählt);- Sprache (Ihrer Dokumente):
- Beschreibung (Ihres Modells und der Dokumente, auf denen es geschult ist).
2. Trainingsdaten
Während des Trainings sind die Ground Truth-Seiten in zwei Gruppen unterteilt:
- Trainingsdaten oder Trainingssatz: Reihe von Beispielen, die verwendet werden, um die Parameter des Modells anzupassen, d. h. die Daten, auf denen das Wissen im Netz basiert. Das Modell wird auf diesen Seiten geschult.
- Validierungsdaten oder Validierungssatz: Reihe von Beispielen, die eine unvoreingenommene Bewertung eines Modells ermöglichen, mit denen die Parameter des Modells während des Trainings abgestimmt werden können. Mit anderen Worten, die Seiten des Validation Sets werden während des Trainings beiseite gelegt und dienen zur Beurteilung ihrer Genauigkeit.
Wählen Sie im unteren Teil des Fensters zunächst die Seiten aus, die Sie in Ihr Trainingsdaten aufnehmen möchten.
Um alle Seiten Ihres Dokuments hinzuzufügen, wählen Sie den Ordner aus und klicken Sie auf „+Schulung“.
Um den Trainingsdaten eine bestimmte Seitenfolge aus Ihrem Dokument hinzuzufügen, doppelklicken Sie auf den Ordner, klicken Sie auf die erste Seite, die Sie einbinden möchten, halten Sie die UMSCHALT-Taste auf Ihrer Tastatur gedrückt und klicken Sie dann auf die letzte Seite. Klicken Sie dann auf „+Training“.
Um einzelne Seiten aus Ihrem Dokument zu den Trainingsdaten hinzuzufügen, doppelklicken Sie auf den Ordner, halten Sie die STRG-Taste auf der Tastatur gedrückt und wählen Sie die Seiten aus, die Sie als Trainingsdaten verwenden möchten. Klicken Sie dann auf „+Training“.
Die von Ihnen ausgewählten Seiten werden im Feld „Training Set“ auf der rechten Seite angezeigt.
Darüber hinaus können Sie entscheiden, welche Transkriptionsversion Sie sowohl für das Übertragungsset als auch für die Validierungsdaten verwenden möchten: aktuellstes Transkript, nur Ground Truth oder anfängliches Transkript. Mit der ersten Option werden alle aktuellen Transkripte, unabhängig davon, wie sie gespeichert wurden, angezeigt und können für das Training ausgewählt werden. Wenn Sie "Ground Truth only" wählen, sind nur die als Ground Truth gespeicherten Seiten auswählbar.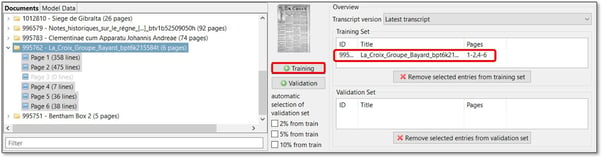
3. Validierungsdaten
Denken Sie daran, dass die Validierungsdaten repräsentativ für die "Ground Truth" sein sollten und alle in den Trainingsdaten enthaltenen Beispiele (Schriften, Hände, Sprachen...) umfassen sollten. Andernfalls, wenn die Validierungsdaten zu wenig variieren, könnte die Messung der Leistung des Modells verzerrt sein.
Wir empfehlen, bei den Validierungsdaten nicht zu sparen und etwa 10 % Ihrer Ground Truth-Transkriptionen zuzuordnen.
Um Seiten zu den Validierungsdaten hinzuzufügen, folgen Sie demselben Prozess wie oben für die Trainingsdaten beschrieben, klicken aber auf die Schaltfläche "+Validierung".
Sie können auch automatisch 2%, 5% oder 10% der Trainingsdaten den Validierungsdaten zuweisen. Wählen Sie die Seiten aus, die Sie zu den Trainingsdaten hinzufügen möchten, markieren Sie den Prozentsatz, den Sie den Validierungsdaten zuweisen möchten, und klicken Sie auf die Schaltfläche "+Training".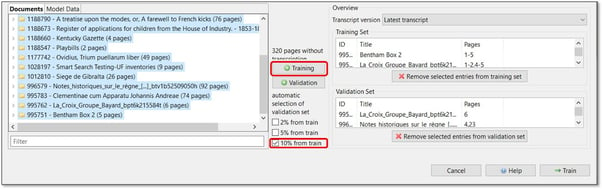
Um Seiten aus dem „Training Set“ oder „Validation Set“ zu entfernen, klicken Sie auf die Seite und dann auf das rote Kreuz.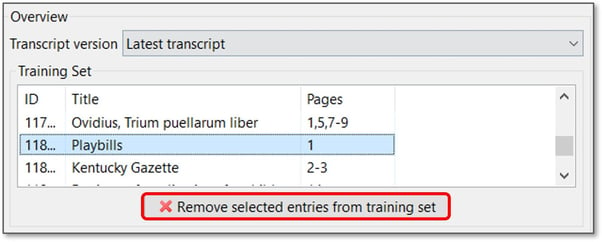
4. Motor
PyLaia ist die Texterkennungs-Engine, die in Transkribus verfügbar ist. Wenn Sie ein Texterkennungsmodell trainieren, wird es mit PyLaia trainiert.
In Zukunft hoffen wir, neue Architekturen in Transkribus zu implementieren und den Benutzern mehr Texterkennungslösungen anzubieten.
5. Erweiterte Parameter
Die Parameter für die PyLaia-Engine in Transkribus eXpert sind in zwei Gruppen unterteilt:
- “Standard Parameters” (im oberen rechten Teil des Fensters, unter “Language”);
- „Erweiterte Parameter“ (erreichbar durch Klicken auf die Schaltfläche unten im Abschnitt Parameter).
Standardparameter:
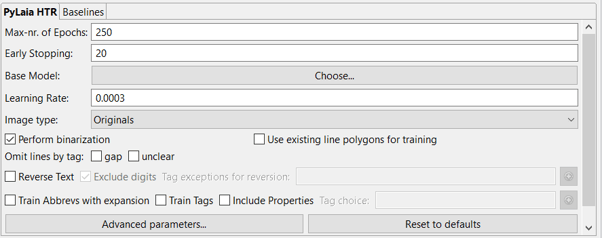
Im Detail sind es:
- Max-nr. of Epochs:
Die Anzahl der Epochen bezieht sich darauf, wie oft der Lernalgorithmus die gesamten Trainingsdaten durchläuft und sich selbst sowohl anhand der Trainings- als auch der Validierungsdaten bewertet.
Sie können die maximale Anzahl der Epochen erhöhen, aber beachten Sie, dass der Trainingsprozess länger dauert. Beachten Sie außerdem, dass das Training automatisch gestoppt wird, wenn sich das Modell nicht mehr verbessert (d. h. es die niedrigstmögliche Cer erreicht hat). Zunächst ist es sinnvoll, die Standardeinstellung von 250 beizubehalten. - Vorzeitiges Beenden:
Dieser Wert legt die Mindestanzahl von Epochen für das Training fest: das Modell wird mindestens so viele Epochen durchlaufen.
Nach Abschluss dieser Epochen, wenn der CER der Validierungsdaten weiter sinkt, wird das Training fortgesetzt und automatisch beendet, wenn sich das Modell nicht mehr verbessert. Wenn die CER hingegen nicht mehr sinkt, wird das Training abgebrochen.
Mit anderen Worten: Mit dem Wert für das frühzeitige Beenden zwingen Sie das Modell, mindestens diese Anzahl von Epochen zu trainieren.
Bei den meisten Modellen funktioniert die Standardeinstellung von 20 Epochen gut, und wir empfehlen, sie für Ihr erstes Training beizubehalten.
Wenn es keine oder nur geringe Variationen im Validation Set gibt, kann das Modell zu früh aufhören. Aus diesem Grund empfehlen wir, ein vielfältiges Validation Set zu erstellen, das alle im Training Set vorhandenen Handtypen und Dokumenttypen enthält.
Nur wenn Ihr Validation Set eher klein ist, sollten Sie den "Early Stopping"-Wert erhöhen, um zu vermeiden, dass das Training abbricht, bevor es das gesamte Training Set gesehen hat. Beachten Sie aber, dass das Training länger dauert, wenn Sie den Wert erhöhen.
- Basismodell:
Bestehende Modelle können als Ausgangspunkte für das Training neuer Modelle verwendet werden. Wenn Sie ein Basismodell auswählen, beginnt das Training nicht bei Null, sondern mit dem Wissen, das das Basismodell bereits erlernt hat. Mit Hilfe eines Basismodells ist es möglich, die Anzahl neuer Ground Truth-Seiten zu reduzieren und so den Trainingsprozess zu beschleunigen. Wahrscheinlich wird das Basismodell auch die Qualität der Erkennungsergebnisse verbessern.
Der Nutzen eines Basismodells ist jedoch nicht immer gewährleistet und muss für den spezifischen Fall getestet werden. < br >Um ein Basismodell zu verwenden, wählen Sie einfach das gewünschte mit der Schaltfläche „Wählen Sie…“ neben „Basismodell“ aus. Sie können eines der öffentlichen PyLaia-Modelle oder ein PyLaia-Modell von Ihnen auswählen. Denken Sie daran, dass das Basismodell, um von Vorteil zu sein, auf einen Schreibstil ähnlich dem Ihres Modells trainiert worden sein muss. - Lernrate:
Die "Lernrate" definiert das Inkrement von einer Epoche zur anderen, also wie schnell das Training abläuft. Bei einem höheren Wert sinkt die Zeichenfehlerrate schneller. Je höher der Wert, desto höher ist jedoch das Risiko, dass Details übersehen werden.
Dieser Wert ist adaptiv und wird automatisch angepasst. Das Training wird jedoch durch den Wert beeinflusst, mit dem es begonnen wird. Hier können Sie mit der Standardeinstellung fortfahren. - Bildtyp:
In einigen Fällen hat die Vorverarbeitung zu viel Zeit in Anspruch genommen. Wenn Ihnen dies passiert, können Sie den „Bildtyp“ auf „Komprimiert“ umstellen.
Sie können folgendermaßen vorgehen: Beginnen Sie das Training mit „Original“. Wenn das Training begonnen hat (Status "Running"), überprüfen Sie ab und zu den Fortschritt der Vorverarbeitung mit der Schaltfläche "Jobs". Falls er stecken bleibt, können Sie den Job abbrechen und mit der „Komprimiert“-Einstellung neu starten.
- Binarisierung durchführen:
Diese Option ist standardmäßig ausgewählt. Entfernen Sie die Markierung und verwenden Sie keine Binarisierung nur, wenn Sie homogene Trainingsdaten haben, d. h. Seiten mit der gleichen Hintergrundfarbe. Nur in diesem Fall kann keine Binarisierung zu besseren Ergebnissen führen. - Bestehende Linienpolygone für das Training verwenden:
Wenn Sie diese Option markieren, werden Linienpolygone während des Trainings nicht berechnet (was standardmäßig der Fall ist), sondern die vorhandenen werden verwendet.
Bei der Erkennung sollten dann ähnliche Linienpolygone verwendet werden, um die beste Leistung des resultierenden trainierten Modells zu erzielen. - Zeilen nach Tag weglassen:
Mit dieser Option können Sie Zeilen mit Wörtern, die mit „Lücke“ und/oder „unklar“ markiert sind, aus dem Training weglassen. Bitte beachten Sie, dass während des Trainings die ganze Zeile ignoriert wird, nicht nur das unklare Wort: Dies geschieht, weil das Training auf Linienebene stattfindet. - Text umkehren:
Verwenden Sie diese Option, um Text während des Trainings umzukehren, wenn die Schreibrichtung im Bild der Transkription entgegengesetzt ist, z. B. der Text wurde von rechts nach links geschrieben und von links nach rechts transkribiert. Sie können auch beschließen, Ziffern oder getaggten Text von der Umkehrung auszuschließen. - Training Tags:
Es ist möglich, Text-Tags und ihre Eigenschaften zu trainieren, wenn sie in der Ground Truth vorhanden sind, so dass das Modell während der Erkennung automatisch Tags generiert. < br >Diese Funktion funktioniert gut mit Abkürzungen und Textstilen und bringt die besten Ergebnisse für Tags, die auf die gleiche Weise wiederholt werden (d. h. das gleiche Wort), sehr oft. < br >Wählen Sie "Train Abbreviations with tags", um die getaggten Abkürzungen ("Abbrev" -Tag) und die entsprechenden "Expansion" -Eigenschaften zu trainieren, die in Ihrer Ground Truth vorhanden sind.
Für andere Tags wählen Sie die Option "Train Tags" und klicken Sie auf "Include Properties". Verwenden Sie die grüne Plus-Schaltfläche, um die Liste der Tags einzugeben, die trainiert werden sollen. Beachten Sie, dass Sie hier nur die Tags auswählen können, die der Gruppe „Tag-Spezifikation“ hinzugefügt wurden.
Erweiterte Parameter:
Benutzer können mehrere erweiterte Parameter von PyLaia selbst festlegen. Sie können die erweiterten Parameter öffnen, indem Sie auf die Schaltfläche „Erweiterte Parameter“ am unteren Rand der Standardparameter klicken.
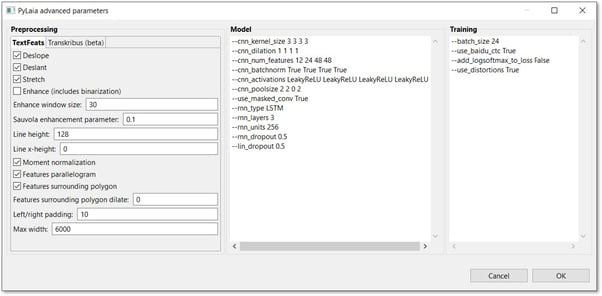
Sie sind in drei Gruppen unterteilt: Vorverarbeitung, Modell und Schulung.
- Vorverarbeitungs-Parameter:
- Deslant: Wählen Sie diese Option mit kursiver Schrift, um sie zu begradigen. Verzichten Sie bei gedruckten Dokumenten auf diese Option, denn wenn gedruckte Dokumente zusätzlich zu den normalen Druckzeichen kursive Passagen enthalten, kann der Effekt auf dem Kopf stehen.
- Deslope : ermöglicht mehr Variation an den Basislinien, z. B. mehr Toleranz an Basislinien, die nicht genau horizontal, sondern schräg sind. < strong> Dehnung: Diese Option ist für schmales Schreiben, um es zu entkomprimieren.
- Verbessern: Das ist ein Fenster, das über die Basislinien geht, um schwer lesbare Passagen zu optimieren. Dies ist nützlich, wenn Sie "Lärm" im Dokument haben.
- Fenstergröße erweitern : Diese Einstellung bezieht sich auf die gerade erläuterte Option und muss daher nur festgelegt werden, wenn Sie "Erweitern" verwenden möchten. Diese Einstellung definiert die Größe des Fensters.
- Sauvola-Verbesserungsparameter: Bitte halten Sie sich hier an die Standardeinstellung.
- Zeilenhöhe: Wert in Pixeln; wenn Sie die Pixel der Zeile erhöhen müssen, können Sie dies hier tun. 100 ist ein guter Wert, den Sie wählen sollten.
Achtung: Wenn der Wert zu hoch ist, kann dies zu einer "Reihenfolge außerhalb des Speichers" führen. Sie können diesen Fehler wiederum umgehen, indem Sie den Wert der „Losgröße“ (oben links im Fenster mit den erweiterten Parametern) verringern, z. B. um die Hälfte. Bitte beachten Sie, dass das Training umso langsamer wird, je niedriger dieser Wert ist. Die Verlangsamung der Schulung in Bezug auf die Chargengröße sollte mit der neuen Version von PyLaia verbessert werden, die die Chargengröße automatisch einstellt. - Zeile x-Höhe: Diese Einstellung gilt für die Unter- und Oberlängen. Wenn Sie diesen Wert eingeben, wird der Parameter "Zeilenhöhe" ignoriert.
- Bitte ändern Sie nicht die folgenden vier Parameter:
Momentnormalisierung
Merkmale Parallelogramm
Merkmale umgebendes Polygon
Merkmale umgebendes Polygondilatatat - Innenabstand links/rechts:10 (Standard) bedeutet, dass 10 Pixel hinzugefügt werden. Dies ist nützlich, wenn Sie befürchten, dass Teile der Leitung abgeschnitten werden könnten.
- Maximale Breite: maximale Breite, die eine Linie erreichen kann; der Rest wird abgeschnitten. 6000 (Standard) ist bereits ein hoher Wert. Wenn Sie große Seiten haben, können Sie diesen Wert weiter erhöhen.
- Modellparameter:
Für alle, die mit maschinellem Lernen und der Modifikation von neuronalen Netzen vertraut sind. Daher werden diese Parameter hier nicht weiter erläutert.
- Trainingsparameter:
- Stapelgröße: Anzahl der Seiten, die gleichzeitig in der GPU verarbeitet werden. Sie können diesen Wert ändern, indem Sie eine andere Zahl eingeben.
- Use_distortions True: Das Trainingsset wird künstlich erweitert, um die Variation des Trainingssets zu erhöhen und so das Modell robuster zu machen. Wenn Sie sogar an Schreiben und guten Scans arbeiten, benötigen Sie diese Option nicht. Um es zu deaktivieren, schreiben Sie bitte „Falsch“ statt „Wahr“.
- Die Netzstruktur von PyLaia kann auch geändert werden – ein Spielplatz für Menschen, die mit maschinellem Lernen vertraut sind. Änderungen am neuronalen Netz können über Github-Repository vorgenommen werden.
An diesem Punkt können Sie das Training starten, indem Sie auf die Schaltfläche „Trainieren“ klicken.
Sie können den Fortschritt der Schulung verfolgen, indem Sie auf der Registerkarte „Server“ auf die Schaltfläche „Jobs“ klicken. Abhängig vom Datenverkehr auf den Servern und der Menge an Material kann Ihr Training eine Weile dauern. Im Fenster „Jobs“ können Sie Ihre Position in der Warteschlange überprüfen (d. h. die Anzahl der Schulungen vor Ihnen). Sie können andere Aufgaben in Transkribus ausführen oder das Programm während des Schulungsprozesses schließen. Wenn der Auftragsstatus "erstellt" oder "ausgeführt" ist, beginnen Sie bitte keine neue Schulung, sondern haben Sie einfach Geduld und warten Sie.
Nachdem das Training begonnen hat, wird der Abschluss jeder Epoche in der Stellenbeschreibung angezeigt und Sie erhalten eine E-Mail, wenn der Trainingsprozess abgeschlossen ist.